FRASER staff strive to make complete runs of publications available, from the start of a title to the present. For currently published titles, we download the most recent issues from the document producer’s website. This usually proves efficient, and these “born digital” files provide users with clean images and searchable text that can also be copied and pasted without the OCR (optical character recognition) errors that tend to creep into scanned documents.
For example, FRASER holds a full run of The Employment Situation news release produced by the Bureau of Labor Statistics. We scanned the 1966-1993 publications. The remaining years came digitally from the BLS’s archive. The 1994-2002 publications were in TXT format (later converted to PDFs, as described below) and the 2002-present publications are PDFs. PDFs are preferred over other formats because they can be displayed and navigated with FRASER’s in-page PDF viewer and table of contents tool.
While bulk conversion to PDF is a simple process, PDFs of the 1994-2002 TXT files created in this manner were visually disorganized and appeared converted from TXT rather than mimicking the printed documents (Figure 1). Creating metadata for tables of contents also proved very time consuming, as tables started at irregular places in the PDFs. After some thought and experimentation, we developed a macro in Microsoft Word to reformat TXT files for improved PDF conversion.
Here’s how the process works:
- Open the TXT files in Word.
- Run the Word macro on the open files, which includes these steps:
- Resize pages and adjust page margins to fit the majority of pages.
- Find text that typically indicates a page header and insert a page break.
- Find and reduce text blocks too big to fit a standard page.
- Save the files in DOCX format with the same file names.
- Manually scroll through the formatted documents to check page breaks and adjust as necessary.
- Save the files.
- Convert the files to PDF using an Acrobat batch process.
Voila! The resulting PDFs are much more visually organized (Figure 2) than those previously produced, and creating metadata for tables of contents takes less time—allowing us to move on to new FRASER projects sooner.

Figure 1. Sample of 2 Pages, Straight Conversion from TXT to PDF
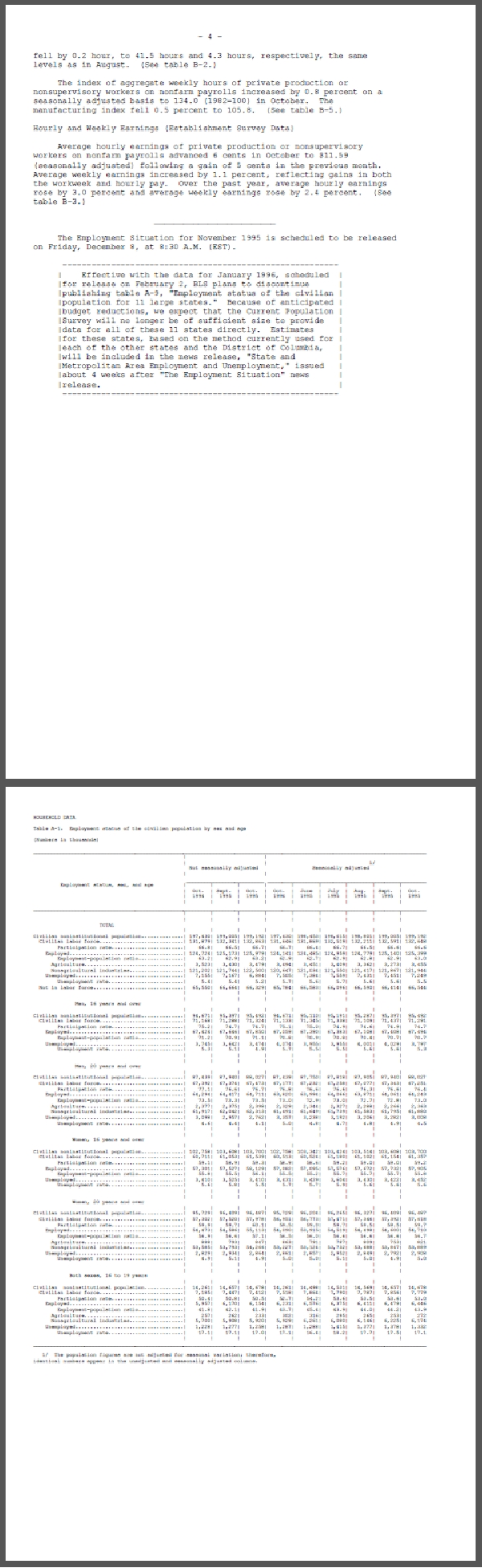
Figure 2. Sample of 2 pages, Conversion from TXT to PDF with Macro (available at https://fraser.stlouisfed.org/scribd/?item_id=494663&filepath=/files/docs/releases/bls/bls_employnews_199510.pdf&start_page=4)