Could the text in historical documents like those in FRASER help to predict future financial trends? This is a question explored in the area of study known as sentiment analysis. The practice of assessing public opinion in text in order to forecast future events goes back centuries.[1] More recently, and for decades, researchers inside and outside of the Federal Reserve System have studied the way people (including central bankers) have talked about the economy, to look for patterns that might help predict future changes in economic activity. Today, new computer-based ways of parsing existing texts allow more content to be analyzed more quickly and on a larger scale.
Sentiment analysis is a kind of “natural language processing,” an artificial intelligence analysis method in which computers “read” a text and interpret it in some specifically programmed way. Some sentiment analysis tools do this by referencing a dictionary of words that have been rated “negative” or “positive” by the tool builder. Other sentiment analysis tools use “machine learning” algorithms that train a computer to analyze data a certain way.[2] Regardless of the specific tool used, the aim is to analyze text and provide a positive, negative, or neutral sentiment score based on the wording used. For example, consider this sentence:
The crisis has exposed fundamental weaknesses in financial systems worldwide, demonstrated how interconnected and interdependent economies are today, and has posed vexing policy dilemmas.[3]
This sentence would likely receive a negative sentiment score based on the relatively high number of words rated as negative in the given context: crisis, exposed, weaknesses, and vexing. Now consider this sentence:
It has made this Nation and Government an impregnable financial force and the strongest the mind of man has devised.[4]
This sentence would likely receive a positive sentiment score based on the numbers of words rated as positive in the given context: impregnable and strongest. Note that most robust sentiment analysis tools also consider the context of a word, so that a phrase like “not good” will be interpreted as a negative sentiment, despite the fact that “good” alone expresses a positive sentiment.
Researchers studying finance and the economy are particularly interested in sentiment analysis because of its potential ability to analyze text, particularly news, to predict future economic trends. So far, automated sentiment analysis hasn’t proven helpful in this regard, but the sophistication of these tools improves every year.
To test how sentiment analysis might be used with documents in FRASER, we recently conducted an experiment to see what insights it could glean from all issues of a single publication—The Economic Report of the President. Released annually since 1947, the report presents an overall summary of the financial health of the United States and echoes attitudes about the economy at the time it was written.
To begin, we first needed to gather the text of the reports to create a dataset. While this could be done a number of ways (including just downloading every report and then copying and pasting the text from the PDF), we opted to use FRASER’s API to programmatically download all 79 volumes of the report and then extract all the text from the PDF files using a Python[5]package called PyMuPDF.
Next, we needed a way to actually score the sentiment. We could have constructed a program from scratch, creating a scored dictionary and developing an algorithm to parse the texts, but fortunately there are a number of “out of the box” solutions. Many of these tools are free and open source and can be found on sites like Github. For this experiment we chose VADER Sentiment Analysis. The package allows you to feed in a sentence and get back a score that looks like this:
{‘neg’: 0.105, ‘neu’: 0.526, ‘pos’: 0.368, ‘compound’: 0.7906}
Here’s what that says: For the sentence scored, roughly 10% of the words are negative, 53% are neutral, and 37% are positive. The compound score is the net sentiment score for the entire sentence, which is calculated by adding up the scores of each word in the sentence and then normalizing that number to a value between –1 and 1. In this case, the value 0.7906 represents a strong positive compound sentiment.
For our FRASER test case, we first looked at the average positive, negative, and neutral scores for each year (report). These were calculated by first getting the sum of total positive, negative, and neutral scores for each sentence in each report and dividing each of those numbers by the total number of sentences in the report.
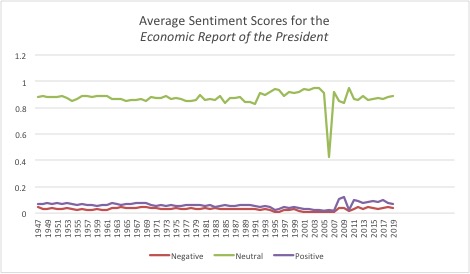
These data already show something interesting: While sentiments about the economy have stayed mostly consistent—and neutral—since 1947, there was a sudden drop in neutral sentiments in 2006, followed by a sharp increase in positive sentiments in the next few years.
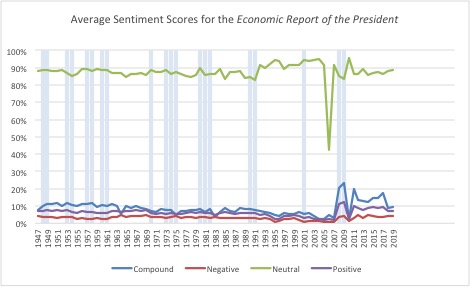
A: 1947-2019 (Gray-blue bars indicate recessions as determined by the National Bureau of Economic Research)
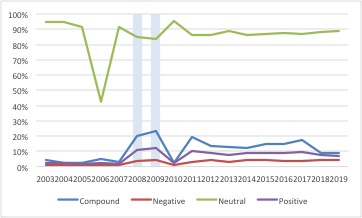
B: 2003-2019
NOTE: Dates of U.S. Recessions as Inferred by NBER-Based Recession Indicator.
Could it be that in the year leading up to the largest financial crisis since the Great Depression, there was an implicit warning in the use of less-neutral language? Maybe—but there could also be a hidden cause for this outlier in the data: Older volumes of the report are more likely to be prone to errors in the optical character recognition (OCR) process, while newer volumes are more likely to be “born digital” (originally created with a computer) and therefore have cleaner text.
For example, here is what the computer “sees” in a passage from page 12 of the 1947 Economic Report of the President:

We can double-check the reliability of the data by looking at the average compound score of each sentence across reports. In this case, we are categorizing each sentence of a report as either positive, negative, or neutral as a whole, rather than calculating the percentage or words that are weighted toward one of the sentiments. Theoretically, this would lessen the effect of incorrect OCR on the overall sentiment score.

This view also appears to show a shift in the language used after 2006, with upticks in both positive and negative sentiments during the years of the financial crisis.
While it may not be a novel idea to suggest that the years of the financial crisis elicited more polarized language in the president’s economic report, it is interesting to see it quantified in this way. What else might we deduce from this data? The sharp return to neutral language in 2010, around the end the crisis, suggests a return to normalcy. The greater proportions of both negative and positive sentences in subsequent years, however, may indicate a trend toward more polarized language in general.
This is all to say that sentiment analysis may be able to reveal new insights or even confirm ideas already held. While collections in FRASER have been used by researchers to explore how politically independent the Fed is, how the FOMC dissent functions, and to build new datasets, FRASER’s large runs of publications present potentially untapped opportunities for AI-assisted research.
[1] Mika Mäntylä, Daniel Graziotin, and Miikka Kuutila. “The Evolution of Sentiment Analysis – A Review of Research Topics, Venues, and Top Cited Papers.” Computer Science Review, February 2018, 27: 16-32.
[2] Santiago Pinto. “Sentiment Analysis of the Fifth District Manufacturing and Service Surveys.” Federal Reserve Bank of Richmond Economic Quarterly, Third Quarter 2019, 105(3): 138.
[3] Excerpted from “The Global Financial Crisis: Analysis and Policy Implications,” a 2009 Congressional Research Service report.
[4] Excerpted from a speech by Comptroller of the Currency John Skelton Williams quoted in “The Federal Reserve Act: Its Origin and Principles,” a 1918 booklet by Robert Owen.
[5] Python is an open-source general purpose programming language that is popular for machine learning applications.
© 2020, Federal Reserve Bank of St. Louis. The views expressed are those of the author(s) and do not necessarily reflect official positions of the Federal Reserve Bank of St. Louis or the Federal Reserve System.
